Aby móc w dalszej części dokumentu lepiej rozumieć treść zaczniemy od wyjaśnienia niektórych pojęć, które wiążą się z bazami danych. Z pewnością z większością z nich już się zetknęliśmy, a niektóre nawet można wręcz samemu wyjaśnić. Niemniej zacznijmy od wyjaśnienia i rozwinięcia skrótów.
// JDBC
// poniższe zapytanie zostanie wysłane do bazy danych, gdzie dopiero tam
// będzie weryfikacja jego poprawności
PreparedStatement ps = conn.prepareStatement("SELECT ename, sal FROM emp
WHERE sal > ?");
double minSal = 1000.00;
ps.setDouble(1, minSal);
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String n = rs.getString("ENAME");
double s = rs.getDouble("SAL");
System.out.println(n + " " + s);
}
rs.close();
ps.close();
// SQLJ
// w tym przypadku, przy kompilacji zostanie sprawdzone, czy zapytanie
// jest poprawnie zbudowane
#sql iterator EmpNameIter(String ename, double sal);
...
EmpNameIter iter;
double minSal = 1000.00;
#sql iter = { SELECT ename, sal FROM emp WHERE sal > :minSal };
while (iter.next()) {
String n = iter.ename();
double s = iter.sal();
System.out.println(n + " " + s);
}
iter.close();
W celu skorzystania z ODBC w systemie Windows musimy najpierw zarejestrować źródło danych.
Robimy to wybierając Panel sterowania -> Źródła danych ODBC lub Panel sterowania -> Narzędzia administracyjne -> Źródła danych ODBC (zależnie od wersji Windows). Na zakładce DNS użytkownika wybieramy Dodaj... a następnie w nowo otwartym oknie wybieramy odpowiedni sterownik dla naszej bazy danych. Standardowo możemy wybrać sterownik dla bazy danych Microsoft Access (Microsoft Access Driver (*.mdb)). Powinno pojawić się okno, którego jedną z najistotniejszych części jest nazwa źródła danych (DSN - Data Source Name), której teraz będziemy używać do identyfikacji naszej bazy. Następnie przyciskamy Wybierz... W części Baza danych podajemy plik .mdb, gdzie mamy naszą baze danych (lub gdzie chcemy ją utworzyć). Tak wygląda najprostsza rejestracja bazy pod Windows.
JDBC jak każdy produkt ma swoje zalety i wady. Poniżej przedstawiam po dwie z nich
java.sql.Niezależnie od tego z jaką bazą danych chcemy się połączyć zawsze odbywa się to w 2 krokach:
W pierwszym kroku musimy załadować odpowiednią klasę tak, aby była ona dostępna podczas próby nawiązania połączenia. Robimy to w następujący sposób:
Class.forName(className);
Connection connection = DriverManager.getConnection(url);
Parametr url to adres bazy, z którą chcemy się połączyć.
Klasa java.sql.DriverManager, jak można wnioskować z jej nazwy, to klasa zarządzająca całym naszym połączeniem. Jej najbardziej interesującymi metodami są statyczne metody getConnection(). Innym wariantem tej metody jest:
Connection getConnection (String url, String user, String password),
którą stosujemy, gdy połączenie z wybranym źródłem danych (parametr url) wymaga uwierzytelnienia. Po wywołaniu tej metody DriverManager sprawdza, która ze znanych mu klas rozpoznaje url. Jeśli taką znajdzie powierza jej nawiązanie połączenia.
Jeśli wszystko się powiedzie połączenie zostanie nawiązane i dalej będziemy się posługiwali obiektem connection.
Jak łatwo zauważyć głównym problemem jest to, jakie powinny być wartości parametrów className i url.
Jeśli mamy juz utworzone źródło danych ODBC (patrz roz.1.2), to możemy w łatwy sposób wykorzystać je w naszym programie. Poniższy kod ładuje odpowiedni sterownik (dostępny standardowo w SDK):
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
W tym momencie jesteśmy już gotowi do nawiązania połączenia:
Connection con = DriverManager.getConnection("jdbc:odbc:Fred", "Fernanda", "J8");
URL naszej bazy danych składa się z 3 części
jdbc - nazwa protokołuodbc - nazwa podprotokołuFred - nazwa źródła danych (DSN - Data Source Name), podanego podczas tworzenia źródła danych ODBC (patrz roz.1.2)"Fernanda" i "J8", to nazwa użytkownika i hasło niezbędne podczas uwierzytelniania.
Jeśli z jakiś powodów nie możemy lub nie chcemy wykorzystać ODBC możemy połączyć się z bazą danych bezpośrednio przez JDBC. Jednak w tym wypadku konieczne będą sterowniki odpowiednie dla naszej bazy danych. Sterowniki takie są zwykle darmowe i dostępne w internecie. Po ich ściągnięciu powinniśmy otrzymać plik jar, który musi być dostępny podczas kompilacji programu. Możemy to zrobić np. dodając deklarację zmiennej systemowej CLASSPATH w pliku autoexec.bat.
Poniżej znajdują się 2 przykłady, bazy danych: MySQL i Interbase.
Sterownik JDBC dla MySQL nazywa się Connector/J (analogicznie dla ODBC Connector/ODBC).
Klasą, którą należy zarejestrować jest com.mysql.jdbc.Driver, zaś typowy adres źródła danych wygląda następująco:
"jdbc:mysql://[host]:[port]/[DSN]"
[host] - adres hosta, jeśli go pominiemy nastąpi próba połączenia z localhost[port] - numer portu[DSN] - nazwa źródła danychJaybird jest sterownikiem JDBC dla open source'owej bazy danych Firebird, jednak dobrze się również sprawuje z bazą danych Interbase.
Klasą, którą należy zarejestrować jest org.firebirdsql.jdbc.FBDriver, zaś typowy adres źródła danych wygląda tak:
"jdbc:firebirdsql:localhost/3050:D:\\Moje dokumenty\\baza.gdb"
Kiedy już nawiązaliśmy połączenie możemy zacząć operować na bazie danych. Ogólny schemat przedstawia poniższy rysunek:
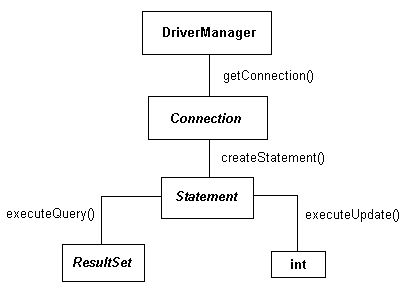
Po nawiązaniu połączenia powinniśmy utworzyć wyrażenie (Statement), które posłuży do wykonywania zapytań. Wynikiem wykonania zapytania może być albo tabela (ResultSet), albo, w przypadku aktualizacji bazy danych, liczba wierszy, które uległy zmianie (int).
W pierwszym przykładzie chcemy utworzyć prostą tabelę o nazwie Sells, która zawiera trzy kolumny: bar, beer i price. Polecenie to będzie wyglądało niemalże jak w SQL. Najpierw podajemy słowa kluczowe CREATE TABLE, następnie występuje nazwa tabeli. Po tym w nawiasie umieszczamy nazwy kolumn oraz ich rodzaje (typy), oddzielając poszczególne składowe przecinkiem. Do dyspozycji mamy wiele typów: FLOAT, INTEGER, VARCHAR(wielkość_napisu), itd. Przykładowe zdanie w SQL wygląda następująco:
CREATE TABLE Sells
(bar VARCHAR(40), beer VARCHAR(40), price REAL)
Następnie, jeśli chcemy zadać jakieś zapytania do bazy, to generujemy zdania takie jak w zwykłym SQL, tzn dla przykładu pobranie wszystkiego z tabeli Sells to bedzie:
SELECT * FROM Sells
Podobnie wstawienie jednego wiersza do tabeli Sells przedstawia się następująco:
INSERT INTO Sells VALUES
('Bar Of Madness', 'Rycerskie mocne', 3.50)
Wiemy już jak tworzyć zapytania do bazy, czas, aby je w praktyce zastosować. Aby wykonać zapytanie należy najpierw utworzyć obiekt typu Statement, tworzy się go poprzez obiekt typu Connection. Wygląda to następująco:
Statement stmt = con.createStatement();
Teraz wystarczy wykonać operację pobrania danych z bazy lub aktualizacji bazy. Robimy to poprzez opisany wyżej obiekt stmt. Nadmienić należy, iż możemy w trojaki sposób zadać zapytanie do bazy; poprzez stmt.executeQuery(...), stmt.executeUpdate(...), stmt.execute(...). Różni się to sposobem przekazywania wyniku. W pierwszym przypadku otrzymamy wynik w postaci tabeli. Jest to nasz wynik zapytania. W drugim przypadku otrzymamy ilość pomyślnie przeprowadzonych zmian w naszej bazie. Trzecia opcja jest uogólnieniem dwóch poprzednich. Zwraca wynik, tyle, że to my musimy sami sprawdzić jaki wynik dostaliśmy. executeQuery() stosuje się zazwyczaj do zapytań typu SELECT...., a executeUpdate() do zapytań typu CREATE TABLE... lub INSERT... Oto przykłady jak stosować wstawianie do bazy kilku rekordów:
Statement s = conn.createStatement();
s.executeUpdate("CREATE TABLE Sells " +
"(bar VARCHAR(40), beer VARCHAR(40), price REAL)" ) ;
s.executeUpdate("INSERT INTO Sells VALUES " +
"('Bar Of Madness', 'Rycerskie mocne', 3.50)" ) ;
s.executeUpdate("INSERT INTO Sells VALUES " +
"('Bar Of Alibi', 'Sikacz rozcienczony', "4.50)" ) ;
s.executeUpdate("INSERT INTO Sells VALUES " +
"('Bar Of G.A.F.A', 'Zywiec', 5.00)" ) ;
Wykonaliśmy zapytania, baza nam się wzbogaciła o nowe rekordy. Dobrze, ale jak je teraz odczytać? Do tego celu przydatny nam będzie obiekt typy ResultSet. Używa się go przy odczycie danych, jakie zwróciła nam baza po wykonaniu operacji SELECT. Wygląda to tak:
ResultSet rs = s.executeQuery("SELECT * FROM Sells") ;
Teraz w rs mamy kolekcję rekordów, jakie zwróciła nam baza (ściślej mówiąc są tam tylko wskaźniki na odpowiednie rekordy, fizycznie wynik jest trzymany po stronie bazy danych). Obiekt rs możemy sobie wyobrazić jako tabelę, po której możemy chodzić, pobierać interesujące nas dane. W rzeczywistości czy to jest tabela czy lista to zależy od nas. Do dyspozycji mamy takie warianty jak: lista jednokierunkowa, lista dwukierunkowa, tablica. Oczywiście im bardziej wygodna forma dla nas tym mniej efektywna. W poniższych przykładach zajmować będziemy się tylko listą jednokierunkową.
Analiza rekordów odbywa się poprzez przechodzenie od początku listy do końca (lub odwrotnie). Startujemy z tak zwanego przedpola, czyli znacznik na nasza listę jest ustawiony tuż przed pierwszym elementem. Aby dostać się do następnego rekordu (u nas początkowo do pierwszego) stosujemy rs.next(). I tak wiersz po wierszu analizujemy dane, aż do ostatniego elementu listy. Wygląda to następująco:
String bar, beer ;
float price ;
while( rs.next() ) {
bar = rs.getString("bar");
beer = rs.getString("beer");
price = rs.getFloat("price");
}
W wyniku czego dostaniemy przy każdym przebiegu pętli zapełnienie wartości bar, beer, price wartościami z poszczególnych wierszy tabeli.
Jak zauważyliśmy do pobrania wartości stosujemy metody np. getString(nazwa_kolumny). Ogólnie metoda getXXX() służy do pobrania wartości typu XXX z podanej kolumny. W Java mamy zaimplementowanych wiele rodzajów, przykładowe metody pobierania danych to: getString(..), getFloat(..), getLong(..), getBoolean(..), getObject(...) oraz wiele innych.
Do kolumny możemy się odwoływać poprzez bezpośrednie podanie nazwy kolumny jak powyżej (np. getString("bar")) lub liczby odpowiadającej kolumnie z której pobieramy dane np. getString(1).
Interfejsem podobnym do Statement jest PreparedStatement (właściwie jest to podinterfejs). Tworzy się go tak samo jak Statement, jednak sposób użycia jest nieco inny:
PreparedStatement prepStatement = c.prepareStatement(" +
"INSERT INTO Sells VALUES (?, ?, ?)");
Wartości kryjące się pod pytajnikami należy wypełnić odpowiednimi danymi. Obiekt ten tworzy się w celu uniknięcia wielokrotnego powtarzania kodu (parametryzacja). Zwykle takie zapytanie (zależy to od implementacji) jest prekompilowane przez bazę danych, więc np. przy wstawianiu wielu rekordów naraz, korzystanie z niego powinno być szybsze od standardowego wyrażenia (Statement). Po stworzeniu takiego wyrażenia możemy w miejsce pytajników wstawiać wartości parametrów. Tak to się przedstawia:
PreparedStatement prepStatement = c.prepareStatement(" +
"INSERT INTO Sells VALUES (?, ?, ?)");
prepStatement.setString(1, "Bar Of Od Zmierzchu do Switu");
prepStatement.setString(2, "Okocim");
prepStatement.setFloat(3, (float)4.50);
prepStatement.executeUpdate();
prepStatement.setString(1, "Bar Of Przekret");
prepStatement.setString(2, "Ksiaz");
prepStatement.setFloat(3, (float)3.50);
prepStatement.executeUpdate();
Jak można się domyślić metody setXXX(int, XXX) wstawiają w miejsce znaków zapytania odpowiednie wartości. Pierwszy parametr to numer znaku zapytania (numerujemy od 1), zaś drugi to wartość, którą chcemy wstawić.
Jak widać kod jest znacznie bardziej przejrzysty oraz łatwiejszy w obsłudze. Poza tym mamy zyski w szybkości działania, gdyż tak sformułowane zapytanie wędruje do bazy, gdzie jest odkładane na stercie. Następnie, gdy zadajemy zapytanie przez sieć wędrują jedynie poszczególne elementy składowe zapytania, a nie całe zapytanie, czyli sieć jest o wiele mniej obciążona oraz baza ma mniej do parsowania.
Innym sposobem polepszania efektywności bazy jest stosowanie Batch. Jest to mechanizm pozwalający nam wysyłać zapytania do bazy nie w postaci pojedynczych zapytań, ale skumulowanych po kilka. Jest to ponownie odciążanie sieci, gdyż nie przesyłamy za każdym razem całego zapytania i nie otrzymujemy po jednej odpowiedzi, a gromadzimy po kilka zapytań i otrzymujemy tyle samo odpowiedzi. Wygląda to następująco:
Statement stm = c.createStatement();
stm.addBatch("INSERT INTO Sells VALUES " +
"('Bar Of PRL', 'Zywiec', 6.00)");
stm.addBatch("INSERT INTO Sells VALUES " +
"('Bar Of Kompres', 'Tatra', 3.50)");
stm.addBatch("INSERT INTO Sells VALUES " +
"('Bar Of Tawerna', 'Warka', 4.00)");
// gdy dodaliśmy już wszystkie zapytania wysyłamy
// je do bazy
stm.executeBatch();
Połączenie mechanizmów Batch i PreparedStatement daje w wyniku taki oto efekt:
PreparedStatement pstm = c.prepareStatement(" +
"INSERT INTO Sells VALUES (?, ?, ?)");
pstm.setString(1, "Bar of Kuznia");
pstm.setString(2, "Piast");
pstm.setFloat(3, (float)4.00);
pstm.addBatch();
pstm.setString(1, "Bar of Intro");
pstm.setString(2, "Zywiec");
pstm.setFloat(3, (float)5.00);
pstm.addBatch();
pstm.executeBatch();
Każda aktualizacja bazy danych (np. poprzez metodę executeUpdate()) żeby mieć trwały efekt musi zostać potwierdzona (ang. commit). Domyślnie połączenie jest ustawione tak, aby automatycznie potwierdzać każdą operację (ang. auto commit), tzn. po wykonaniu każdej aktualizacji jest automatycznie wysyłane potwierdzenie. Należy zauważyć, że wszystkie niepotwierdzone aktualizacje w wypadku np. zerwania połączenia powinny zostać cofnięte (tak działa większość baz danych). Tak więc jeśli chcemy dokonać transakcji wystarczy wyłączyć automatyczne potwierdzanie:
connection.setAutoCommit(false);
Teraz każda operacja aktualizacji zostanie odnotowana w bazie danych, ale jej efekt nie będzie widoczny dopóki nie wyślemy potwierdzenia:
connection.commit();
Jeśli w którymś momencie wykonywania aktualizacji zostanie zgłoszony wyjątek możemy zażądać cofnięcia wszystkich zmian aż do ostatniego potwierdzenia:
connection.rollback();
Istotne jest, że zmiany już potwierdzone nie mogą zostać anulowane metodą rollback(). Tak więc standardowy schemat transakcji wygląda następująco:
connection.setAutoCommit(false);
try
{
statement.executeUpdate(...);
statement.executeUpdate(...);
statement.executeUpdate(...);
connection.commit();
}
catch (SQLException ex)
{
connection.rollback();
}
connection.setAutoCommit(true);
Connection getConnection(String url) - nawiązuje połączenie ze źródłem danych urlStatement createStatement () - tworzy wyrażeniePreparedStatement prepareStatement (String stm) - tworzy prekompilowane wyrażenie o treści stmvoid setAutoCommit (boolean b) - ustawia automatyczne potwierdzanie na bvoid commit () - potwierdza wszystkie nie potwierdzone, a wykonane zapytania dla tego połączeniavoid rollback () - cofa wszystkie nie potwierdzone zapytania dla tego połączeniavoid close () - zamyka to połączenieResultSet executeQuery (String query) - wykonuje zapytanie o treści queryint executeUpdate (String query) - wykonuje aktualizację o treści queryboolean execute (String query) - wykonuje zapytanie lub aktualizację o treści queryResultSet getResultSet () - zwraca zbiór wynikowy ostatniego zapytania>boolean next () - ustawia znacznik na następny wierszXXX getXXX (int columnNumber) - zwraca wartość z kolumny columnNumber o typie XXXXXX getXXX (String columnName) - zwraca wartość z kolumny o nazwie columnName o typie XXX